CloudNativePG je open-source Kubernetes operátor pro PostgreSQL od EnterpriseDB. CNPG řeší vše kolem PostgreSQL clusteru: vytvoření, škálování, zálohování, obnovu, monitoring a další.
Co je CloudNativePG?
CloudNativePG je open-source Kubernetes operátor: co to ale znamená? Operátor je speciální aplikace, která běží na Kubernetes a řídí životní cyklus jiných aplikací. V případě CNPG je to PostgreSQL cluster.
CNPG řeší všechno, co náš PostgreSQL cluster potřebuje: vytvoření, zálohy, obnovu záloh, škálování, Point In Time Recovery (PITR), monitoring s podporou Promethea a Grafany. Ale třeba i automatický failover, pokud se něco stane s primární instancí nebo můžete vyvolat switchover ručně.
Cluster
V CNPG je hlavní Cluster objekt, který popisuje a reprezentuje celý PostgreSQL
cluster v Kubernetes. Cluster může mít jednu nebo více PostgreSQL instancí
které spravuje. Dále Cluster obsahuje konfiguraci pro zálohování, monitoring,
replikaci, PostgreSQL parametry a další.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: my-db
spec:
imageName: ghcr.io/cloudnative-pg/postgresql:17
instances: 3
primaryUpdateStrategy: unsupervised
primaryUpdateMethod: switchover
superuserSecret:
name: superuser-credentials # Secret with superuser credentials
storage:
storageClass: standard
size: 100Gi
resources:
limits:
cpu: "4"
memory: 16Gi
requests:
cpu: "4"
memory: 16Gi
bootstrap:
recovery:
backup:
name: before-longhorn-migration
## Postgres configuration ##
# Enable 'postgres' superuser
enableSuperuserAccess: true
# Postgres instance parameters
postgresql:
parameters:
max_connections: "500"
max_slot_wal_keep_size: "10GB"
wal_keep_size: "5GB"
# High Availability configuration
minSyncReplicas: 1
maxSyncReplicas: 1
# Enable replication slots for HA in the cluster
replicationSlots:
highAvailability:
enabled: true
monitoring:
enablePodMonitor: true
backup:
retentionPolicy: "7d"
barmanObjectStore:
tags:
backupRetentionPolicy: "expire"
historyTags:
backupRetentionPolicy: "keep"
destinationPath: "s3://my-db-backups/backups"
# for other object stores
# endpointURL: "http://10.10.10.10:9000"
wal:
compression: bzip2
data:
compression: bzip2
s3Credentials:
accessKeyId:
name: backup-credentials
key: s3AccessKey
secretAccessKey:
name: backup-credentials
key: s3SecretKeyCNPG vytvoří tři Kubernetes Service pro připojení:
my-db-rw: pro čtení a zápis, vždy míří na primary instancimy-db-ro: pouze pro čtení, vždy míří synchronní replikymy-db-r: pro čtení, míří na primary nebo replika instanci
CNPG umí spravovat PostgreSQL clustery pouze v rámci jednoho Kubernetes clusteru. Nemůžete tedy mít PostgreSQL cluster napříč větším množstvím Kubernetes clusterů.
pgBouncer
apiVersion: postgresql.cnpg.io/v1
kind: Pooler
metadata:
name: pgbouncer
spec:
cluster:
name: my-db
instances: 3
type: rw
pgbouncer:
poolMode: session
parameters:
# 3 replicas with 100 connections = 300 connections total
# postgres has max of 500 connections
max_client_conn: "100"
default_pool_size: "10"
ignore_startup_parameters: "search_path"
deploymentStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
monitoring:
enablePodMonitor: true
# PodTemplateSpec
template:
metadata:
labels:
app.kubernetes.io/name: pooler
spec:
containers: [] # suppress error
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- pooler
topologyKey: kubernetes.io/hostname # node hostnameZálohování
CNPG zálohuje do objektového úložiště (S3, GCS, Azure Blob Storage) pomocí Barman (který je také open-source od EnterpriseDB).
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: backup-my-db
spec:
schedule: "0 40 0 * * *"
backupOwnerReference: self
cluster:
name: my-dbCNPG ponechává zálohy v tzv. floating-window formátu. To znamená, že staré
zálohy maže, až v momentě kdy je vytvořen dostatečný počet nových záloh a vy
nepřícházíte o možnost obnovy v daném časovém okně. Okno se nastavuje v
spec.backup.retentionPolicy.
Point In Time Recovery
Pokud máte nastavené automatické zálohování, můžete využít i možnosti archivování WALů (Write Ahead Log). Díky těm můžete obnovit databázi do stavu v konkrétní čas. Tím minimalizujete ztrátu času v případě výpadku do řádu jednotek sekund.
Co je dobré zmínit, zálohování WALů je náročné na přenos dat. Jednotlivé WALy mají sice pár megabytů, ale pokud máte “ukecanou” aplikaci, můžete mít několik desítek WALů za minutu, což se při nahrávání do cloudu může na transferu a ukládání dat prodražit.
Příklad: databáze měla cca 20 GB, komprimované zálohy za posledních 7 dnů měly dohromady pod 100 GB, ale WALy měly cca 500 GB. To je 500 GB, které se nahrají každý týden do cloudu, za měsíc to jsou tedy 2 TB. Je tedy značný nepoměr mezi zálohami a WALy.
Replica cluster
Za mě jednou z nejzajímavějších funkcí CNPG je tzv. replica cluster.
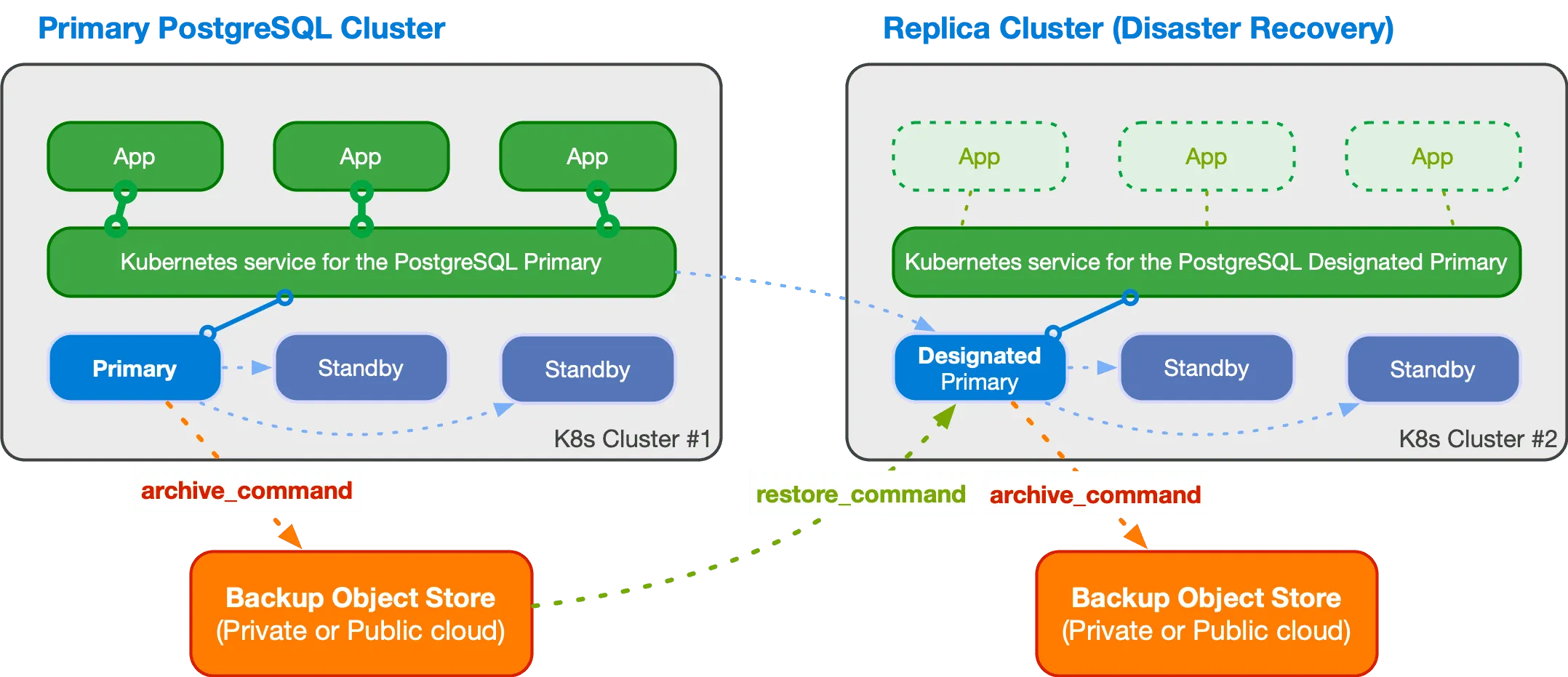
Tedy PostgreSQL cluster, který si stahuje data z object storage a tím se synchronizuje s primárním clusterem. Je tedy možné tím mít druhý “stand-by” cluster například v jiné lokaci.
Samozřejmě takový cluster má vždy zpoždění o několik sekund až minut, záleží jak často se na primárním clusteru tvoří nové WALy.
Nový cluster má pak tzv. designated primary, který je primární instancí ve druhém clusteru a dále pak replikace probíhá standardním způsobem v PostgreSQL. Aby však bylo možné přepnout druhý cluster jako hlavní, je nutné tento switchover/failover provést ručně. CNPG nemá nástroj, jak tuto změnu provádět automaticky. A s přihlédnutím ke stabilitě řešení možná ani takovou věc automaticky dělat nechcete.
Pokud vás zajímá víc, podívejte se do dokumentace.
kubectl plugin
CNPG má i vlastní kubectl plugin, který umožňuje interakci s PostgreSQL
clustery.
Instalovat se dá snadno pomocí kubectl krew (kubectl plugin manager):
kubectl krew install cnpgA pak můžete používat kubectl cnpg:
kubectl cnpg status my-dbS kubectl cnpg můžete tvořit zálohy kdykoliv chcete, měnit nastavení clusteru,
sledovat stav clusteru a další. Za mě rozhodně plugin doporučuji, je to skvělý
pomocník pro správu PostgreSQL clusteru.
PostgreSQL na Kubernetes: vlastní managed služba
Díky CNPG tedy můžete v podstatě bezstarostně (alespoň taková je moje zkušenost v rámci cybroslabs) na Kubernetes provozovat PostgreSQL cluster, jako kdyby to byla managed služba od AWS, Azure nebo Google Cloud.
Největším problémem pro nás byla vlastně poněkud špatná konfigurace, kterou jsme museli odladit, ale o tom píšu v následující sekci Na co si dát pozor.
Na co si dát pozor
Samozřejmě, jako u každé technologie, i u CNPG je třeba si dávat pozor, na některé věci. Ze zkušenosti to jsou jmenovitě tři: upgrady operátoru, načasování změn konfigurace a zdraví clusteru a konfigurace replik.
Upgrady opertátoru
Co je dobré vědět je, že při upgradu operátoru se automaticky restartují všechny PostgreSQL clustery. Což pokud máte náročné aplikace které hodně využívají dlouho otevřená spojení, neplánovaný restart nemusí být ideální.
Pokud nasadíte ke clusteru i pgBouncer, může vám to pomoci a režii znovuotevírání spojení necháte na něm, ale i tak to může mít dopad na latenci, což pro real-time aplikace může být problém.
Změny clusteru jen když je zdravý cluster
Další věc, na kterou si dát pozor, je změna konfigurace clusteru. Pokud chcete
měnit konfiguraci clusteru, ať změnou manifestu nebo přes kubectl cnpg.
Pokud cluster není Healthy, není možné nic měnit. Což v běžných podmínkách je nepříjemné, ale opertátor typicky dokončí změny v řádu minut a pak je možné opět s clusterem aktivně pracovat.
Pokud ale je cluster v “rozbitém” stavu, je to problém. Myslete tedy na to a pokud se cluster dostane zpátky do zdravého stavu, začne okamžitě aplikovat změny, které jste chtěli udělat, když cluster nebyl zdravý.
Konfigurace replik
Počet instancí PostgreSQL se definuuje pod spec.instances. Jeden je vždy
primary a ostatní repliky. Jestli jsou synchronní nebo asynchronní repliky
se nastavuje pod spec.minSyncReplicas a spec.maxSyncReplicas.
A tady přichází řekněme “záludnost”. Pokud máte instances=3,
minSyncReplicas=1 a maxSyncReplicas=1, tak je vše v pořádku a vždy v
clusteru máte minimálně jednu synchronní repliku, ale i dvě.
Pokud ale nastavíte instances=3, minSyncReplicas=1 a maxSyncReplicas=2,
cluster se přestává chovat stabilně. Proto se takovému nastavení vyhněte.
Více o konfiguraci replik najdete v dokumentaci.
